Solving Quantum Mechanical Many-body Problems with Machine Learning Algorithms
University of Trento, March 12, 2019. Codes and slides at https://github.com/mhjensenseminars/MachineLearningTalk
What is this talk about?
The main aim is to give you a short and pedestrian introduction to how we can use Machine Learning methods to solve quantum mechanical many-body problems. And why this could be of interest.
The hope is that after this talk you have gotten the basic ideas to get you started. Peeping into https://github.com/mhjensenseminars/MachineLearningTalk, you'll find a Jupyter notebook, slides, codes etc that will allow you to reproduce the simulations discussed here, and perhaps run your own very first calculations.
Try it out and please don't hesitate to swing by if something is unclear.
Why?
How can we avoid the dimensionality curse? Many possibilities
- smarter basis functions
- resummation of specific correlations
- stochastic sampling of high-lying states (stochastic FCI, CC and SRG/IMSRG)
- many more
Machine Learning and Quantum Computing hold also great promise in tackling the ever increasing dimensionalities. Here we will focus on Machine Learning.
Overview
- Short intro to Machine Learning
- Variational Monte Carlo (Markov Chain Monte Carlo, \( \mathrm{MC}^2 \)) and two-electron quantum dots, solving quantum mechanical problems in a stochastic way. It will serve as our motivation for switching to Machine Learning.
- From Variational Monte Carlo to Boltzmann Machines and Machine Learning
- And a link to so-called Shadow wave functions
What are the Machine Learning calculations here based on?
This work is inspired by the idea of representing the wave function with a restricted Boltzmann machine (RBM), presented recently by G. Carleo and M. Troyer, Science 355, Issue 6325, pp. 602-606 (2017). They named such a wave function/network a neural network quantum state (NQS). In their article they apply it to the quantum mechanical spin lattice systems of the Ising model and Heisenberg model, with encouraging results.
Thanks to Jane Kim (MSU), Vilde Flugsrud (UiO), Alfred Alocias Mariadason (UiO) for many discussions and interpretations.
A new world
Machine learning (ML) is an extremely rich field, in spite of its young age. The increases we have seen during the last three decades in computational capabilities have been followed by developments of methods and techniques for analyzing and handling large date sets, relying heavily on statistics, computer science and mathematics. The field is rather new and developing rapidly.
Popular software packages written in Python for ML are
- Scikit-learn,
- Tensorflow,
- PyTorch and
- Keras.
These are all freely available at their respective GitHub sites. They encompass communities of developers in the thousands or more. And the number of code developers and contributors keeps increasing.
Lots of room for creativity
Not all the algorithms and methods can be given a rigorous mathematical justification, opening up thereby for experimenting and trial and error and thereby exciting new developments.
A solid command of linear algebra, multivariate theory, probability theory, statistical data analysis, optimization algorithms, understanding errors and Monte Carlo methods is important in order to understand many of the various algorithms and methods.
Job market, a personal statement: A familiarity with ML is almost becoming a prerequisite for many of the most exciting employment opportunities. And add quantum computing and there you are!
Knowledge of Statistical analysis and optimization of data
Some key elements that enter much of the discussion on ML:- Basic concepts, expectation values, variance, covariance, correlation functions and errors;
- Simpler models, binomial distribution, the Poisson distribution, simple and multivariate normal distributions;
- Central elements of Bayesian statistics and modeling;
- Central elements from linear algebra
- Gradient methods for data optimization
- Monte Carlo methods, Markov chains, Metropolis-Hastings algorithm;
- Estimation of errors using cross-validation, blocking, bootstrapping and jackknife methods;
- Practical optimization using Singular-value decomposition and least squares for parameterizing data.
- Principal Component Analysis.
Some members of the ML family
- Linear regression and its variants, Logistic regression
- Decision tree algorithms, from simpler to more complex ones like random forests
- Bayesian statistics
- Support vector machines and finally various variants of
- Artifical neural networks (NN) and deep learning
- Convolutional NN, autoenconders, Recurrent NN, Boltzmann machines
- and many more
What are the basic ingredients?
Almost every problem in ML and data science starts with the same ingredients:
- The dataset \( \mathbf{x} \) (could be some observable quantity of the system we are studying)
- A model which is a function of a set of parameters \( \mathbf{\alpha} \) that relates to the dataset, say a likelihood function \( p(\mathbf{x}\vert \mathbf{\alpha}) \) or just a simple model \( f(\mathbf{\alpha}) \)
- A so-called cost function \( \mathcal{C} (\mathbf{x}, f(\mathbf{\alpha})) \) which allows us to decide how well our model represents the dataset.
We seek to minimize the function \( \mathcal{C} (\mathbf{x}, f(\mathbf{\alpha})) \) by finding the parameter values which minimize \( \mathcal{C} \). This leads to various minimization algorithms.
What is Machine Learning?
Machine learning is the science of giving computers the ability to learn without being explicitly programmed. The idea is that there exist generic algorithms which can be used to find patterns in a broad class of data sets without having to write code specifically for each problem. The algorithm will build its own logic based on the data.
Machine learning is a subfield of computer science, and is closely related to computational statistics. It evolved from the study of pattern recognition in artificial intelligence (AI) research, and has made contributions to AI tasks like computer vision, natural language processing and speech recognition. It has also, especially in later years, found applications in a wide variety of other areas, including bioinformatics, economy, physics, finance and marketing.
You will notice however that many of the basic ideas discussed here come from Physics!
Types of Machine Learning
The approaches to machine learning are many, but are often split into two main categories. In supervised learning we know the answer to a problem, and let the computer deduce the logic behind it. On the other hand, unsupervised learning is a method for finding patterns and relationship in data sets without any prior knowledge of the system. Some authours also operate with a third category, namely reinforcement learning. This is a paradigm of learning inspired by behavioural psychology, where learning is achieved by trial-and-error, solely from rewards and punishment.
Another way to categorize machine learning tasks is to consider the desired output of a system. Some of the most common tasks are:
- Classification: Outputs are divided into two or more classes. The goal is to produce a model that assigns inputs into one of these classes. An example is to identify digits based on pictures of hand-written ones. Classification is typically supervised learning.
- Regression: Finding a functional relationship between an input data set and a reference data set. The goal is to construct a function that maps input data to continuous output values.
- Clustering: Data are divided into groups with certain common traits, without knowing the different groups beforehand. It is thus a form of unsupervised learning.
References
- An excellent reference, Mehta et al., arXiv:1803.08823 and Physics Reports in press (2018)
- A cute paper by Utama and Piekarewicz, Validating neural-network refinements of nuclear mass models, Phys. Rev. C 97, 014306
- Every issue of Physical Review Letters has now one or more articles on ML
- Books and lectures notes and see also the course FYS-STK3155/4155
- See also Metha and Schwab, arXiv.1410.3831, how to link Variational renormalization group theory with deep learning (recommended read)
Another interesting article
Here we will use so-called reduced Boltzmann Machines to simulate quantum many-body problems. For Monte Carlo aficionados, there is a very close similarity with what are called shadow wave functions, see the work of Pederiva and Kalos and collaborators, Phys Rev. E 90, 053304 (2014).
Decision trees and Regression
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
steps=250
distance=0
x=0
distance_list=[]
steps_list=[]
while x<steps:
distance+=np.random.randint(-1,2)
distance_list.append(distance)
x+=1
steps_list.append(x)
plt.plot(steps_list,distance_list, color='green', label="Random Walk Data")
steps_list=np.asarray(steps_list)
distance_list=np.asarray(distance_list)
X=steps_list[:,np.newaxis]
#Polynomial fits
#Degree 2
poly_features=PolynomialFeatures(degree=2, include_bias=False)
X_poly=poly_features.fit_transform(X)
lin_reg=LinearRegression()
poly_fit=lin_reg.fit(X_poly,distance_list)
b=lin_reg.coef_
c=lin_reg.intercept_
print ("2nd degree coefficients:")
print ("zero power: ",c)
print ("first power: ", b[0])
print ("second power: ",b[1])
z = np.arange(0, steps, .01)
z_mod=b[1]*z**2+b[0]*z+c
fit_mod=b[1]*X**2+b[0]*X+c
plt.plot(z, z_mod, color='r', label="2nd Degree Fit")
plt.title("Polynomial Regression")
plt.xlabel("Steps")
plt.ylabel("Distance")
#Degree 10
poly_features10=PolynomialFeatures(degree=10, include_bias=False)
X_poly10=poly_features10.fit_transform(X)
poly_fit10=lin_reg.fit(X_poly10,distance_list)
y_plot=poly_fit10.predict(X_poly10)
plt.plot(X, y_plot, color='black', label="10th Degree Fit")
plt.legend()
plt.show()
#Decision Tree Regression
from sklearn.tree import DecisionTreeRegressor
regr_1=DecisionTreeRegressor(max_depth=2)
regr_2=DecisionTreeRegressor(max_depth=5)
regr_3=DecisionTreeRegressor(max_depth=7)
regr_1.fit(X, distance_list)
regr_2.fit(X, distance_list)
regr_3.fit(X, distance_list)
X_test = np.arange(0.0, steps, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
y_3=regr_3.predict(X_test)
# Plot the results
plt.figure()
plt.scatter(X, distance_list, s=2.5, c="black", label="data")
plt.plot(X_test, y_1, color="red",
label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="green", label="max_depth=5", linewidth=2)
plt.plot(X_test, y_3, color="m", label="max_depth=7", linewidth=2)
plt.xlabel("Data")
plt.ylabel("Darget")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
Artificial neurons
The field of artificial neural networks has a long history of development, and is closely connected with the advancement of computer science and computers in general. A model of artificial neurons was first developed by McCulloch and Pitts in 1943 to study signal processing in the brain and has later been refined by others. The general idea is to mimic neural networks in the human brain, which is composed of billions of neurons that communicate with each other by sending electrical signals. Each neuron accumulates its incoming signals, which must exceed an activation threshold to yield an output. If the threshold is not overcome, the neuron remains inactive, i.e. has zero output.
This behaviour has inspired a simple mathematical model for an artificial neuron.
$$
y = f\left(\sum_{i=1}^n w_ix_i\right) = f(u)
$$
Here, the output \( y \) of the neuron is the value of its activation function, which have as input
a weighted sum of signals \( x_i, \dots ,x_n \) received by \( n \) other neurons.
A simple perceptron model
Neural network types
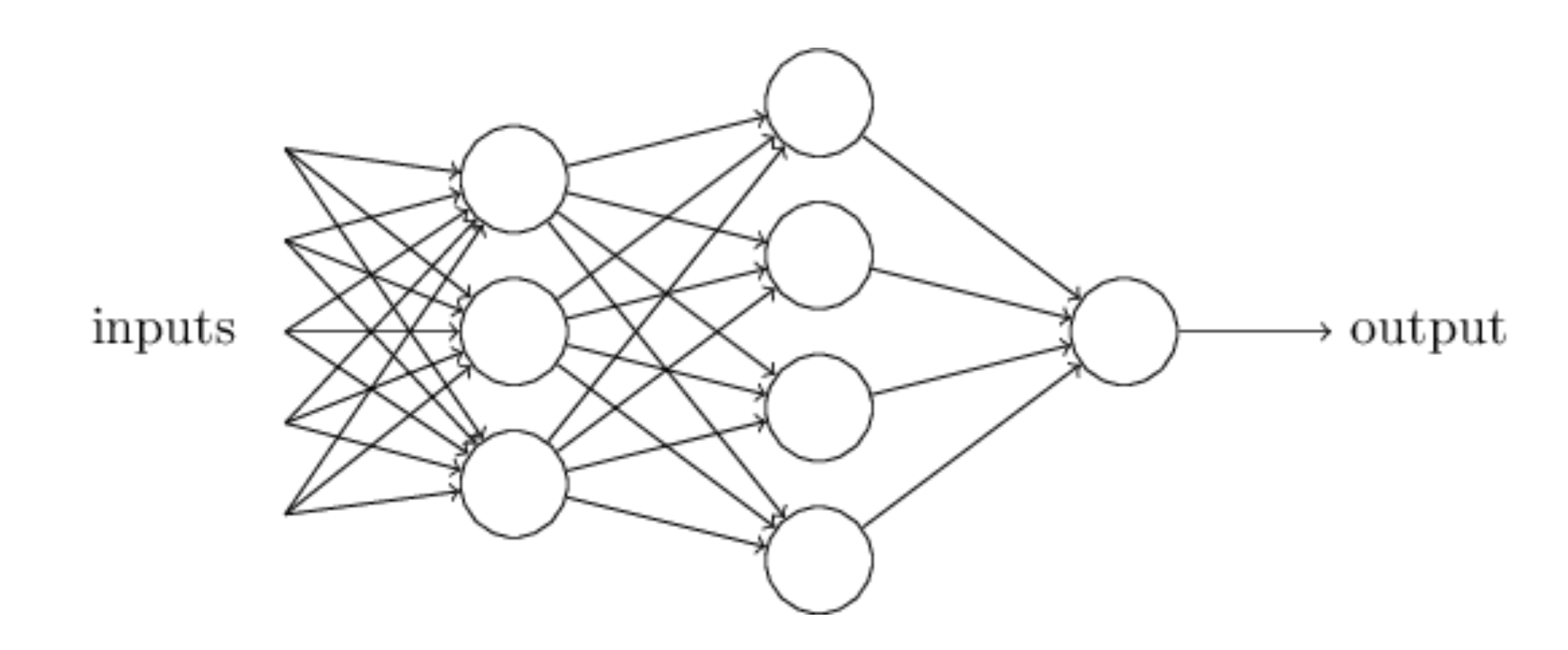
An artificial neural network (NN), is a computational model that consists of layers of connected neurons, or nodes. It is supposed to mimic a biological nervous system by letting each neuron interact with other neurons by sending signals in the form of mathematical functions between layers. A wide variety of different NNs have been developed, but most of them consist of an input layer, an output layer and eventual layers in-between, called hidden layers. All layers can contain an arbitrary number of nodes, and each connection between two nodes is associated with a weight variable.
The system: two electrons in a harmonic oscillator trap in two dimensions
The Hamiltonian of the quantum dot is given by
$$ \hat{H} = \hat{H}_0 + \hat{V},
$$
where \( \hat{H}_0 \) is the many-body HO Hamiltonian, and \( \hat{V} \) is the
inter-electron Coulomb interactions. In dimensionless units,
$$ \hat{V}= \sum_{i < j}^N \frac{1}{r_{ij}},
$$
with \( r_{ij}=\sqrt{\mathbf{r}_i^2 - \mathbf{r}_j^2} \).
This leads to the separable Hamiltonian, with the relative motion part given by (\( r_{ij}=r \))
$$
\hat{H}_r=-\nabla^2_r + \frac{1}{4}\omega^2r^2+ \frac{1}{r},
$$
plus a standard Harmonic Oscillator problem for the center-of-mass motion.
This system has analytical solutions in two and three dimensions (M. Taut 1993 and 1994).
Quantum Monte Carlo Motivation
Given a hamiltonian \( H \) and a trial wave function \( \Psi_T \), the variational principle states that the expectation value of \( \langle H \rangle \), defined through
$$
\langle E \rangle =
\frac{\int d\boldsymbol{R}\Psi^{\ast}_T(\boldsymbol{R})H(\boldsymbol{R})\Psi_T(\boldsymbol{R})}
{\int d\boldsymbol{R}\Psi^{\ast}_T(\boldsymbol{R})\Psi_T(\boldsymbol{R})},
$$
is an upper bound to the ground state energy \( E_0 \) of the hamiltonian \( H \), that is
$$
E_0 \le \langle E \rangle.
$$
In general, the integrals involved in the calculation of various expectation values are multi-dimensional ones. Traditional integration methods such as the Gauss-Legendre will not be adequate for say the computation of the energy of a many-body system.
Quantum Monte Carlo Motivation
Choose a trial wave function \( \psi_T(\boldsymbol{R}) \).
$$
P(\boldsymbol{R},\boldsymbol{\alpha})= \frac{\left|\psi_T(\boldsymbol{R},\boldsymbol{\alpha})\right|^2}{\int \left|\psi_T(\boldsymbol{R},\boldsymbol{\alpha})\right|^2d\boldsymbol{R}}.
$$
This is our model, or likelihood/probability distribution function (PDF). It depends on some variational parameters \( \boldsymbol{\alpha} \).
The approximation to the expectation value of the Hamiltonian is now
$$
\langle E[\boldsymbol{\alpha}] \rangle =
\frac{\int d\boldsymbol{R}\Psi^{\ast}_T(\boldsymbol{R},\boldsymbol{\alpha})H(\boldsymbol{R})\Psi_T(\boldsymbol{R},\boldsymbol{\alpha})}
{\int d\boldsymbol{R}\Psi^{\ast}_T(\boldsymbol{R},\boldsymbol{\alpha})\Psi_T(\boldsymbol{R},\boldsymbol{\alpha})}.
$$
Quantum Monte Carlo Motivation
$$
E_L(\boldsymbol{R},\boldsymbol{\alpha})=\frac{1}{\psi_T(\boldsymbol{R},\boldsymbol{\alpha})}H\psi_T(\boldsymbol{R},\boldsymbol{\alpha}),
$$
called the local energy, which, together with our trial PDF yields
$$
\langle E[\boldsymbol{\alpha}] \rangle=\int P(\boldsymbol{R})E_L(\boldsymbol{R},\boldsymbol{\alpha}) d\boldsymbol{R}\approx \frac{1}{N}\sum_{i=1}^NE_L(\boldsymbol{R_i},\boldsymbol{\alpha})
$$
with \( N \) being the number of Monte Carlo samples.
Quantum Monte Carlo
The Algorithm for performing a variational Monte Carlo calculations runs thus as this
- Initialisation: Fix the number of Monte Carlo steps. Choose an initial \( \boldsymbol{R} \) and variational parameters \( \alpha \) and calculate \( \left|\psi_T(\boldsymbol{R},\boldsymbol{\alpha})\right|^2 \).
- Initialise the energy and the variance and start the Monte Carlo calculation by looping over trials.
- Calculate a trial position \( \boldsymbol{R}_p=\boldsymbol{R}+r*step \) where \( r \) is a random variable \( r \in [0,1] \).
- Metropolis algorithm to accept or reject this move \( w = P(\boldsymbol{R}_p,\boldsymbol{\alpha})/P(\boldsymbol{R},\boldsymbol{\alpha}) \).
- If the step is accepted, then we set \( \boldsymbol{R}=\boldsymbol{R}_p \).
- Update averages
- Finish and compute final averages.
Observe that the jumping in space is governed by the variable step. This is often called brute-force sampling. Need importance sampling to get more relevant sampling.
The trial wave function
We want to perform a Variational Monte Carlo calculation of the ground state of two electrons in a quantum dot well with different oscillator energies, assuming total spin \( S=0 \). Our trial wave function has the following form
$$
\begin{equation}
\psi_{T}(\boldsymbol{r}_1,\boldsymbol{r}_2) =
C\exp{\left(-\alpha_1\omega(r_1^2+r_2^2)/2\right)}
\exp{\left(\frac{r_{12}}{(1+\alpha_2 r_{12})}\right)},
\tag{1}
\end{equation}
$$
where the variables \( \alpha_1 \) and \( \alpha_2 \) represent our variational parameters.
Why does the trial function look like this? How did we get there? This will one of our main motivations for switching to Machine Learning.
The correlation part of the wave function
To find an ansatz for the correlated part of the wave function, it is useful to rewrite the two-particle local energy in terms of the relative and center-of-mass motion. Let us denote the distance between the two electrons as \( r_{12} \). We omit the center-of-mass motion since we are only interested in the case when \( r_{12} \rightarrow 0 \). The contribution from the center-of-mass (CoM) variable \( \boldsymbol{R}_{\mathrm{CoM}} \) gives only a finite contribution. We focus only on the terms that are relevant for \( r_{12} \) and for three dimensions. The relevant local energy operator becomes then (with \( l=0 \))
$$
\lim_{r_{12} \rightarrow 0}E_L(R)=
\frac{1}{{\cal R}_T(r_{12})}\left(-2\frac{d^2}{dr_{ij}^2}-\frac{4}{r_{ij}}\frac{d}{dr_{ij}}+
\frac{2}{r_{ij}}\right){\cal R}_T(r_{12}).
$$
In order to avoid divergencies when \( r_{12}\rightarrow 0 \) we obtain the so-called cusp condition
$$
\frac{d {\cal R}_T(r_{12})}{dr_{12}} = \frac{1}{2}
{\cal R}_T(r_{12})\qquad r_{12}\to 0
$$
Resulting ansatz
The above results in
$$
{\cal R}_T \propto \exp{(r_{ij}/2)},
$$
for anti-parallel spins and
$$
{\cal R}_T \propto \exp{(r_{ij}/4)},
$$
for anti-parallel spins.
This is the so-called cusp condition for the relative motion, resulting in a minimal requirement
for the correlation part of the wave fuction.
For general systems containing more than say two electrons, we have this
condition for each electron pair \( ij \).
The VMC code
# Importing various packages
from math import exp, sqrt
from random import random, seed
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
from matplotlib.ticker import LinearLocator, FormatStrFormatter
import sys
#Trial wave function for quantum dots in two dims
def WaveFunction(r,alpha,beta):
r1 = r[0,0]**2 + r[0,1]**2
r2 = r[1,0]**2 + r[1,1]**2
r12 = sqrt((r[0,0]-r[1,0])**2 + (r[0,1]-r[1,1])**2)
deno = r12/(1+beta*r12)
return exp(-0.5*alpha*(r1+r2)+deno)
#Local energy for quantum dots in two dims, using analytical local energy
def LocalEnergy(r,alpha,beta):
r1 = (r[0,0]**2 + r[0,1]**2)
r2 = (r[1,0]**2 + r[1,1]**2)
r12 = sqrt((r[0,0]-r[1,0])**2 + (r[0,1]-r[1,1])**2)
deno = 1.0/(1+beta*r12)
deno2 = deno*deno
return 0.5*(1-alpha*alpha)*(r1 + r2) +2.0*alpha + 1.0/r12+deno2*(alpha*r12-deno2+2*beta*deno-1.0/r12)
# The Monte Carlo sampling with the Metropolis algo
def MonteCarloSampling():
NumberMCcycles= 100000
StepSize = 1.0
# positions
PositionOld = np.zeros((NumberParticles,Dimension), np.double)
PositionNew = np.zeros((NumberParticles,Dimension), np.double)
# seed for rng generator
seed()
# start variational parameter
alpha = 0.9
for ia in range(MaxVariations):
alpha += .025
AlphaValues[ia] = alpha
beta = 0.2
for jb in range(MaxVariations):
beta += .01
BetaValues[jb] = beta
energy = energy2 = 0.0
DeltaE = 0.0
#Initial position
for i in range(NumberParticles):
for j in range(Dimension):
PositionOld[i,j] = StepSize * (random() - .5)
wfold = WaveFunction(PositionOld,alpha,beta)
#Loop over MC MCcycles
for MCcycle in range(NumberMCcycles):
#Trial position
for i in range(NumberParticles):
for j in range(Dimension):
PositionNew[i,j] = PositionOld[i,j] + StepSize * (random() - .5)
wfnew = WaveFunction(PositionNew,alpha,beta)
#Metropolis test to see whether we accept the move
if random() < wfnew**2 / wfold**2:
PositionOld = PositionNew.copy()
wfold = wfnew
DeltaE = LocalEnergy(PositionOld,alpha,beta)
energy += DeltaE
energy2 += DeltaE**2
#We calculate mean, variance and error ...
energy /= NumberMCcycles
energy2 /= NumberMCcycles
variance = energy2 - energy**2
error = sqrt(variance/NumberMCcycles)
Energies[ia,jb] = energy
return Energies, AlphaValues, BetaValues
#Here starts the main program with variable declarations
NumberParticles = 2
Dimension = 2
MaxVariations = 10
Energies = np.zeros((MaxVariations,MaxVariations))
AlphaValues = np.zeros(MaxVariations)
BetaValues = np.zeros(MaxVariations)
(Energies, AlphaValues, BetaValues) = MonteCarloSampling()
# Prepare for plots
fig = plt.figure()
ax = fig.gca(projection='3d')
# Plot the surface.
X, Y = np.meshgrid(AlphaValues, BetaValues)
surf = ax.plot_surface(X, Y, Energies,cmap=cm.coolwarm,linewidth=0, antialiased=False)
# Customize the z axis.
zmin = np.matrix(Energies).min()
zmax = np.matrix(Energies).max()
ax.set_zlim(zmin, zmax)
ax.set_xlabel(r'$\alpha$')
ax.set_ylabel(r'$\beta$')
ax.set_zlabel(r'$\langle E \rangle$')
ax.zaxis.set_major_locator(LinearLocator(10))
ax.zaxis.set_major_formatter(FormatStrFormatter('%.02f'))
# Add a color bar which maps values to colors.
fig.colorbar(surf, shrink=0.5, aspect=5)
plt.show()
Technical aspect, improvements and how to define the cost function
The above procedure is not the smartest one. Looping over all variational parameters becomes expensive. Also, we don't use importance sampling and optimizations of the standard deviation (blocking, bootstrap, jackknife). Such codes are included in the above Github address.
We can also be smarter and use minimization methods to find the optimal variational parameters with fewer Monte Carlo cycles and then fire up our heavy artillery.
One way to achieve this is to minimize the energy as function of the variational parameters.
Energy derivatives
To find the derivatives of the local energy expectation value as function of the variational parameters, we can use the chain rule and the hermiticity of the Hamiltonian.
Let us define (with the notation \( \langle E[\boldsymbol{\alpha}]\rangle =\langle E_L\rangle \))
$$
\bar{E}_{\alpha_i}=\frac{d\langle E_L\rangle}{d\alpha_i},
$$
as the derivative of the energy with respect to the variational parameter \( \alpha_i \)
We define also the derivative of the trial function (skipping the subindex \( T \)) as
$$
\bar{\Psi}_{i}=\frac{d\Psi}{d\alpha_i}.
$$
Derivatives of the local energy
The elements of the gradient of the local energy are then (using the chain rule and the hermiticity of the Hamiltonian)
$$
\bar{E}_{i}= 2\left( \langle \frac{\bar{\Psi}_{i}}{\Psi}E_L\rangle -\langle \frac{\bar{\Psi}_{i}}{\Psi}\rangle\langle E_L \rangle\right).
$$
From a computational point of view it means that you need to compute the expectation values of
$$
\langle \frac{\bar{\Psi}_{i}}{\Psi}E_L\rangle,
$$
and
$$
\langle \frac{\bar{\Psi}_{i}}{\Psi}\rangle\langle E_L\rangle
$$
These integrals are evaluted using MC intergration (with all its possible error sources).
We can then use methods like stochastic gradient or other minimization methods to find the optimal variational parameters (I don't discuss this topic here, but these methods are very important in ML).
How do we define our cost function?
We have a model, our likelihood function.
How should we define the cost function?
Meet the variance and its derivatives
Suppose the trial function (our model) is the exact wave function. The action of the hamiltionan on the wave function
$$
H\Psi = \mathrm{constant}\times \Psi,
$$
The integral which defines various
expectation values involving moments of the hamiltonian becomes then
$$
\langle E^n \rangle = \langle H^n \rangle =
\frac{\int d\boldsymbol{R}\Psi^{\ast}(\boldsymbol{R})H^n(\boldsymbol{R})\Psi(\boldsymbol{R})}
{\int d\boldsymbol{R}\Psi^{\ast}(\boldsymbol{R})\Psi(\boldsymbol{R})}=
\mathrm{constant}\times\frac{\int d\boldsymbol{R}\Psi^{\ast}(\boldsymbol{R})\Psi(\boldsymbol{R})}
{\int d\boldsymbol{R}\Psi^{\ast}(\boldsymbol{R})\Psi(\boldsymbol{R})}=\mathrm{constant}.
$$
This gives an important information: If I want the variance, the exact wave function leads to zero variance!
The variance is defined as
$$
\sigma_E = \langle E^2\rangle - \langle E\rangle^2.
$$
Variation is then performed by minimizing both the energy and the variance.
The variance defines the cost function
We can then take the derivatives of
$$
\sigma_E = \langle E^2\rangle - \langle E\rangle^2,
$$
with respect to the variational parameters. The derivatives of the variance can then be used to defined the
so-called Hessian matrix, which in turn allows us to use minimization methods like Newton's method or
standard gradient methods.
This leads to however a more complicated expression, with obvious errors when evaluating integrals by Monte Carlo integration. Less used, see however Filippi and Umrigar. The expression becomes complicated
$$
\begin{align}
\bar{E}_{ij} &= 2\left[ \langle (\frac{\bar{\Psi}_{ij}}{\Psi}+\frac{\bar{\Psi}_{j}}{\Psi}\frac{\bar{\Psi}_{i}}{\Psi})(E_L-\langle E\rangle)\rangle -\langle \frac{\bar{\Psi}_{i}}{\Psi}\rangle\bar{E}_j-\langle \frac{\bar{\Psi}_{j}}{\Psi}\rangle\bar{E}_i\right]
\tag{2}\\ \nonumber
&+\langle \frac{\bar{\Psi}_{i}}{\Psi}E_L{_j}\rangle +\langle \frac{\bar{\Psi}_{j}}{\Psi}E_L{_i}\rangle -\langle \frac{\bar{\Psi}_{i}}{\Psi}\rangle\langle E_L{_j}\rangle \langle \frac{\bar{\Psi}_{j}}{\Psi}\rangle\langle E_L{_i}\rangle.
\end{align}
$$
Evaluating the cost function means having to evaluate the above second derivative of the energy.
The code for two electrons in two dims with no Coulomb interaction
We present here the code (including importance sampling) for finding the optimal parameter \( \alpha \) using gradient descent with a given learning rate \( \eta \). In principle we should run calculations for various learning rates.
Again, we start first with set up of various files.
# 2-electron VMC code for 2dim quantum dot with importance sampling
# No Coulomb interaction
# Using gaussian rng for new positions and Metropolis- Hastings
# Energy minimization using standard gradient descent
# Common imports
from math import exp, sqrt
from random import random, seed, normalvariate
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
from matplotlib.ticker import LinearLocator, FormatStrFormatter
import sys
from numba import jit
from scipy.optimize import minimize
# Trial wave function for the 2-electron quantum dot in two dims
def WaveFunction(r,alpha):
r1 = r[0,0]**2 + r[0,1]**2
r2 = r[1,0]**2 + r[1,1]**2
return exp(-0.5*alpha*(r1+r2))
# Local energy for the 2-electron quantum dot in two dims, using analytical local energy
def LocalEnergy(r,alpha):
r1 = (r[0,0]**2 + r[0,1]**2)
r2 = (r[1,0]**2 + r[1,1]**2)
return 0.5*(1-alpha*alpha)*(r1 + r2) +2.0*alpha
# Derivate of wave function ansatz as function of variational parameters
def DerivativeWFansatz(r,alpha):
r1 = (r[0,0]**2 + r[0,1]**2)
r2 = (r[1,0]**2 + r[1,1]**2)
WfDer = -0.5*(r1+r2)
return WfDer
# Setting up the quantum force for the two-electron quantum dot, recall that it is a vector
def QuantumForce(r,alpha):
qforce = np.zeros((NumberParticles,Dimension), np.double)
qforce[0,:] = -2*r[0,:]*alpha
qforce[1,:] = -2*r[1,:]*alpha
return qforce
Then comes our Monte Carlo sampling.
# Computing the derivative of the energy and the energy
# jit decorator tells Numba to compile this function.
# The argument types will be inferred by Numba when function is called.
@jit
def EnergyMinimization(alpha):
NumberMCcycles= 1000
# Parameters in the Fokker-Planck simulation of the quantum force
D = 0.5
TimeStep = 0.05
# positions
PositionOld = np.zeros((NumberParticles,Dimension), np.double)
PositionNew = np.zeros((NumberParticles,Dimension), np.double)
# Quantum force
QuantumForceOld = np.zeros((NumberParticles,Dimension), np.double)
QuantumForceNew = np.zeros((NumberParticles,Dimension), np.double)
# seed for rng generator
seed()
energy = 0.0
DeltaE = 0.0
EnergyDer = 0.0
DeltaPsi = 0.0
DerivativePsiE = 0.0
#Initial position
for i in range(NumberParticles):
for j in range(Dimension):
PositionOld[i,j] = normalvariate(0.0,1.0)*sqrt(TimeStep)
wfold = WaveFunction(PositionOld,alpha)
QuantumForceOld = QuantumForce(PositionOld,alpha)
#Loop over MC MCcycles
for MCcycle in range(NumberMCcycles):
#Trial position moving one particle at the time
for i in range(NumberParticles):
for j in range(Dimension):
PositionNew[i,j] = PositionOld[i,j]+normalvariate(0.0,1.0)*sqrt(TimeStep)+\
QuantumForceOld[i,j]*TimeStep*D
wfnew = WaveFunction(PositionNew,alpha)
QuantumForceNew = QuantumForce(PositionNew,alpha)
GreensFunction = 0.0
for j in range(Dimension):
GreensFunction += 0.5*(QuantumForceOld[i,j]+QuantumForceNew[i,j])*\
(D*TimeStep*0.5*(QuantumForceOld[i,j]-QuantumForceNew[i,j])-\
PositionNew[i,j]+PositionOld[i,j])
GreensFunction = 1.0#exp(GreensFunction)
ProbabilityRatio = GreensFunction*wfnew**2/wfold**2
#Metropolis-Hastings test to see whether we accept the move
if random() <= ProbabilityRatio:
for j in range(Dimension):
PositionOld[i,j] = PositionNew[i,j]
QuantumForceOld[i,j] = QuantumForceNew[i,j]
wfold = wfnew
DeltaE = LocalEnergy(PositionOld,alpha)
DerPsi = DerivativeWFansatz(PositionOld,alpha)
DeltaPsi +=DerPsi
energy += DeltaE
DerivativePsiE += DerPsi*DeltaE
# We calculate mean values
energy /= NumberMCcycles
DerivativePsiE /= NumberMCcycles
DeltaPsi /= NumberMCcycles
EnergyDer = 2*(DerivativePsiE-DeltaPsi*energy)
return energy, EnergyDer
Finally, here we use the gradient descent method with a fixed learning rate and a fixed number of iterations. This code is meant for illustrative purposes only. We could for example add a test which stops the number of terations when the derivative has reached a certain by us fixed minimal value.
#Here starts the main program with variable declarations
NumberParticles = 2
Dimension = 2
# guess for variational parameters
x0 = 0.5
# Set up iteration using stochastic gradient method
Energy =0 ; EnergyDer = 0
Energy, EnergyDer = EnergyMinimization(x0)
# No adaptive search for a minimum
eta = 0.5
Niterations = 50
Energies = np.zeros(Niterations)
EnergyDerivatives = np.zeros(Niterations)
AlphaValues = np.zeros(Niterations)
Totiterations = np.zeros(Niterations)
for iter in range(Niterations):
gradients = EnergyDer
x0 -= eta*gradients
Energy, EnergyDer = EnergyMinimization(x0)
Energies[iter] = Energy
EnergyDerivatives[iter] = EnergyDer
AlphaValues[iter] = x0
Totiterations[iter] = iter
plt.subplot(2, 1, 1)
plt.plot(Totiterations, Energies, 'o-')
plt.title('Energy and energy derivatives')
plt.ylabel('Dimensionless energy')
plt.subplot(2, 1, 2)
plt.plot(Totiterations, EnergyDerivatives, '.-')
plt.xlabel(r'$\mathrm{Iterations}$', fontsize=15)
plt.ylabel('Energy derivative')
plt.show()
#nice printout with Pandas
import pandas as pd
from pandas import DataFrame
data ={'Alpha':AlphaValues, 'Energy':Energies,'Derivative':EnergyDerivatives}
frame = pd.DataFrame(data)
print(frame)
We see that the first derivative becomes smaller and smaller and after some forty iterations, it is for all practical purposes almost vanishing. The exact energy is \( 2.0 \) and the optimal variational parameter is \( 1.0 \), as it should.
Why Boltzmann machines?
What is known as restricted Boltzmann Machines (RMB) have received a lot of attention lately. One of the major reasons is that they can be stacked layer-wise to build deep neural networks that capture complicated statistics.
The original RBMs had just one visible layer and a hidden layer, but recently so-called Gaussian-binary RBMs have gained quite some popularity in imaging since they are capable of modeling continuous data that are common to natural images.
Furthermore, they have been used to solve complicated quantum mechanical many-particle problems or classical statistical physics problems like the Ising and Potts classes of models.
Boltzmann Machines
Why use a generative model rather than the more well known discriminative deep neural networks (DNN)?
- Discriminitave methods have several limitations: They are mainly supervised learning methods, thus requiring labeled data. And there are tasks they cannot accomplish, like drawing new examples from an unknown probability distribution.
- A generative model can learn to represent and sample from a probability distribution. The core idea is to learn a parametric model of the probability distribution from which the training data was drawn. As an example
- A model for images could learn to draw new examples of cats and dogs, given a training dataset of images of cats and dogs.
- Generate a sample of an ordered or disordered Ising model phase, having been given samples of such phases.
- Model the trial function for Monte Carlo calculations
Some similarities and differences from DNNs
- Both use gradient-descent based learning procedures for minimizing cost functions
- Energy based models don't use backpropagation and automatic differentiation for computing gradients, instead turning to Markov Chain Monte Carlo methods.
- DNNs often have several hidden layers. A restricted Boltzmann machine has normally only one hidden layer, however several RBMs can be stacked to make up Deep Belief Networks, of which they constitute the building blocks.
History: The RBM was developed by amongst others Geoffrey Hinton, called by some the "Godfather of Deep Learning", working with the University of Toronto and Google.
Boltzmann machines (BM)
A BM is what we would call an undirected probabilistic graphical model with stochastic continuous or discrete units.
It is interpreted as a stochastic recurrent neural network where the state of each unit(neurons/nodes) depends on the units it is connected to. The weights in the network represent thus the strength of the interaction between various units/nodes.
It turns into a Hopfield network if we choose deterministic rather than stochastic units. In contrast to a Hopfield network, a BM is a so-called generative model. It allows us to generate new samples from the learned distribution.
A standard BM setup
A standard BM network is divided into a set of observable and visible units \( \hat{x} \) and a set of unknown hidden units/nodes \( \hat{h} \).
Additionally there can be bias nodes for the hidden and visible layers. These biases are normally set to \( 1 \).
BMs are stackable, meaning we can train a BM which serves as input to another BM. We can construct deep networks for learning complex PDFs. The layers can be trained one after another, a feature which makes them popular in deep learning
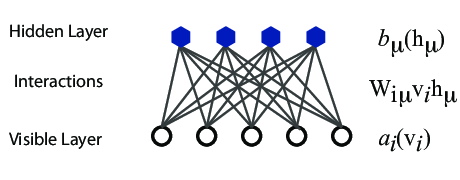
However, they are often hard to train. This leads to the introduction of so-called restricted BMs, or RBMS. Here we take away all lateral connections between nodes in the visible layer as well as connections between nodes in the hidden layer. The network is illustrated in the figure below.
The structure of the RBM network
The network
The network layers:
- A function \( \mathbf{x} \) that represents the visible layer, a vector of \( M \) elements (nodes). This layer represents both what the RBM might be given as training input, and what we want it to be able to reconstruct. This might for example be the pixels of an image, the spin values of the Ising model, or coefficients representing speech.
- The function \( \mathbf{h} \) represents the hidden, or latent, layer. A vector of \( N \) elements (nodes). Also called "feature detectors".
Goals
The goal of the hidden layer is to increase the model's expressive power. We encode complex interactions between visible variables by introducing additional, hidden variables that interact with visible degrees of freedom in a simple manner, yet still reproduce the complex correlations between visible degrees in the data once marginalized over (integrated out).
Examples of this trick being employed in physics:
- The Hubbard-Stratonovich transformation
- The introduction of ghost fields in gauge theory
- Shadow wave functions in Quantum Monte Carlo simulations
The network parameters, to be optimized/learned:
- \( \mathbf{a} \) represents the visible bias, a vector of same length as \( \mathbf{x} \).
- \( \mathbf{b} \) represents the hidden bias, a vector of same lenght as \( \mathbf{h} \).
- \( W \) represents the interaction weights, a matrix of size \( M\times N \).
Joint distribution
The restricted Boltzmann machine is described by a Boltzmann distribution
$$
\begin{align}
P_{rbm}(\mathbf{x},\mathbf{h}) = \frac{1}{Z} e^{-\frac{1}{T_0}E(\mathbf{x},\mathbf{h})},
\tag{3}
\end{align}
$$
where \( Z \) is the normalization constant or partition function, defined as
$$
\begin{align}
Z = \int \int e^{-\frac{1}{T_0}E(\mathbf{x},\mathbf{h})} d\mathbf{x} d\mathbf{h}.
\tag{4}
\end{align}
$$
It is common to ignore \( T_0 \) by setting it to one.
Network Elements, the energy function
The function \( E(\mathbf{x},\mathbf{h}) \) gives the energy of a configuration (pair of vectors) \( (\mathbf{x}, \mathbf{h}) \). The lower the energy of a configuration, the higher the probability of it. This function also depends on the parameters \( \mathbf{a} \), \( \mathbf{b} \) and \( W \). Thus, when we adjust them during the learning procedure, we are adjusting the energy function to best fit our problem.
An expression for the energy function is
$$
E(\hat{x},\hat{h}) = -\sum_{ia}^{NA}b_i^a \alpha_i^a(x_i)-\sum_{jd}^{MD}c_j^d \beta_j^d(h_j)-\sum_{ijad}^{NAMD}b_i^a \alpha_i^a(x_i)c_j^d \beta_j^d(h_j)w_{ij}^{ad}.
$$
Here \( \beta_j^d(h_j) \) and \( \alpha_i^a(x_j) \) are so-called transfer functions that map a given input value to a desired feature value. The labels \( a \) and \( d \) denote that there can be multiple transfer functions per variable. The first sum depends only on the visible units. The second on the hidden ones. Note that there is no connection between nodes in a layer.
The quantities \( b \) and \( c \) can be interpreted as the visible and hidden biases, respectively.
The connection between the nodes in the two layers is given by the weights \( w_{ij} \).
Defining different types of RBMs
There are different variants of RBMs, and the differences lie in the types of visible and hidden units we choose as well as in the implementation of the energy function \( E(\mathbf{x},\mathbf{h}) \).
RBMs were first developed using binary units in both the visible and hidden layer. The corresponding energy function is defined as follows:
$$
\begin{align}
E(\mathbf{x}, \mathbf{h}) = - \sum_i^M x_i a_i- \sum_j^N b_j h_j - \sum_{i,j}^{M,N} x_i w_{ij} h_j,
\tag{5}
\end{align}
$$
where the binary values taken on by the nodes are most commonly 0 and 1.
Another varient is the RBM where the visible units are Gaussian while the hidden units remain binary:
$$
\begin{align}
E(\mathbf{x}, \mathbf{h}) = \sum_i^M \frac{(x_i - a_i)^2}{2\sigma_i^2} - \sum_j^N b_j h_j - \sum_{i,j}^{M,N} \frac{x_i w_{ij} h_j}{\sigma_i^2}.
\tag{6}
\end{align}
$$
Sampling: Metropolis sampling
In order to sample from the RBM probability distribution it is common to use Markov Chain Monte Carlo (MCMC) algorithms such as Metropolis-Hastings or Gibbs sampling.RBMs for the quantum many body problem
The idea of applying RBMs to quantum many body problems was presented by G. Carleo and M. Troyer, working with ETH Zurich and Microsoft Research.
Some of their motivation included
- The wave function \( \Psi \) is a monolithic mathematical quantity that contains all the information on a quantum state, be it a single particle or a complex molecule. In principle, an exponential amount of information is needed to fully encode a generic many-body quantum state.
- There are still interesting open problems, including fundamental questions ranging from the dynamical properties of high-dimensional systems to the exact ground-state properties of strongly interacting fermions.
- The difficulty lies in finding a general strategy to reduce the exponential complexity of the full many-body wave function down to its most essential features. That is
- \( \rightarrow \) Dimensional reduction
- \( \rightarrow \) Feature extraction
- Among the most successful techniques to attack these challenges, artifical neural networks play a prominent role.
- Want to understand whether an artifical neural network may adapt to describe a quantum system.
Choose the right RBM
Carleo and Troyer applied the RBM to the quantum mechanical spin lattice systems of the Ising model and Heisenberg model, with encouraging results. Our goal is to test the method on systems of moving particles. For the spin lattice systems it was natural to use a binary-binary RBM, with the nodes taking values of 1 and -1. For moving particles, on the other hand, we want the visible nodes to be continuous, representing position coordinates. Thus, we start by choosing a Gaussian-binary RBM, where the visible nodes are continuous and hidden nodes take on values of 0 or 1. If eventually we would like the hidden nodes to be continuous as well the rectified linear units seem like the most relevant choice.
Representing the wave function
The wavefunction should be a probability amplitude depending on \( \boldsymbol{x} \). The RBM model is given by the joint distribution of \( \boldsymbol{x} \) and \( \boldsymbol{h} \)
$$
\begin{align}
F_{rbm}(\mathbf{x},\mathbf{h}) = \frac{1}{Z} e^{-\frac{1}{T_0}E(\mathbf{x},\mathbf{h})}.
\tag{7}
\end{align}
$$
To find the marginal distribution of \( \boldsymbol{x} \) we set:
$$
\begin{align}
F_{rbm}(\mathbf{x}) &= \sum_\mathbf{h} F_{rbm}(\mathbf{x}, \mathbf{h})
\tag{8}\\
&= \frac{1}{Z}\sum_\mathbf{h} e^{-E(\mathbf{x}, \mathbf{h})}.
\tag{9}
\end{align}
$$
Now this is what we use to represent the wave function, calling it a neural-network quantum state (NQS)
$$
\begin{align}
\Psi (\mathbf{x}) &= F_{rbm}(\mathbf{x})
\tag{10}\\
&= \frac{1}{Z}\sum_{\boldsymbol{h}} e^{-E(\mathbf{x}, \mathbf{h})}
\tag{11}\\
&= \frac{1}{Z} \sum_{\{h_j\}} e^{-\sum_i^M \frac{(x_i - a_i)^2}{2\sigma^2} + \sum_j^N b_j h_j + \sum_{i,j}^{M,N} \frac{x_i w_{ij} h_j}{\sigma^2}}
\tag{12}\\
&= \frac{1}{Z} e^{-\sum_i^M \frac{(x_i - a_i)^2}{2\sigma^2}} \prod_j^N (1 + e^{b_j + \sum_i^M \frac{x_i w_{ij}}{\sigma^2}}).
\tag{13}\\
\tag{14}
\end{align}
$$
Choose the cost/loss function
Now we don't necessarily have training data (unless we generate it by using some other method). However, what we do have is the variational principle which allows us to obtain the ground state wave function by minimizing the expectation value of the energy of a trial wavefunction (corresponding to the untrained NQS). Similarly to the traditional variational Monte Carlo method then, it is the local energy we wish to minimize. The gradient to use for the stochastic gradient descent procedure is
$$
\begin{align}
C_i = \frac{\partial \langle E_L \rangle}{\partial \theta_i}
= 2(\langle E_L \frac{1}{\Psi}\frac{\partial \Psi}{\partial \theta_i} \rangle - \langle E_L \rangle \langle \frac{1}{\Psi}\frac{\partial \Psi}{\partial \theta_i} \rangle ),
\tag{15}
\end{align}
$$
where the local energy is given by
$$
\begin{align}
E_L = \frac{1}{\Psi} \hat{\mathbf{H}} \Psi.
\tag{16}
\end{align}
$$
Running the codes
You can find the codes for the simple two-electron case at the Github repository https://github.com/mhjensenseminars/MachineLearningTalk/tree/master/doc/Programs/MLcpp/src. Python codes to come, only c++ as of now.
The trial wave function is based on the product of a Slater determinant with Gaussian orbitals, a simple Jastrow factor \( \exp{(r_{ij})} \) and the reduced Boltzmann machines.
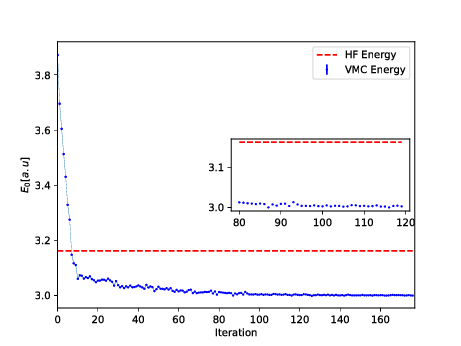
The Broyden-Fletcher-Goldfarb-Shanno algorithm was used for the minimization. We used \( 14 \) hidden nodes in the calculations below.
Energy as function of iterations, \( N=2 \) electrons
Energy as function of iterations, \( N=6 \) electrons
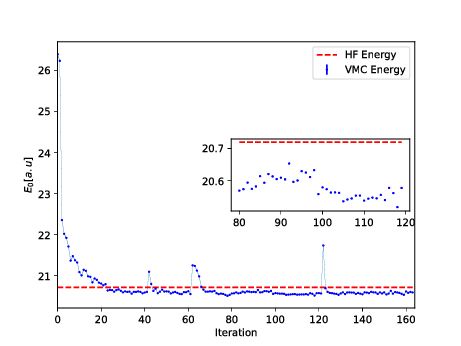
Conclusions and where do we stand
- A simple extension of the work of G. Carleo and M. Troyer, Science 355, Issue 6325, pp. 602-606 (2017) gives excellent results for two-electron systems as well as good agreement with standard VMC calculations for \( N=6 \) and \( N=12 \) electrons.
- Minimization problem can be tricky.
- Anti-symmetry dealt with multiplying the trail wave function with an optimized Slater determinant.
- To come: Analysis of wave function from ML and compare with diffusion and Variational Monte Carlo calculations as well as the analytical results of Taut for the two-electron case.
- Extend to more fermions. How do we deal with the antisymmetry of the multi-fermion wave function?
- Here we used standard Hartree-Fock theory to define an optimal Slater determinant. Takes care of the antisymmetry. What about constructing an anti-symmetrized network function?
- Compare with calculations done with Shadow wave functions.
- Use thereafter ML to determine the correlated part of the wafe function (including a standard Jastrow factor).
- Test this for multi-fermion systems and compare with other many-body methods.
- Can we use ML to find out which correlations are relevant and thereby diminish the dimensionality problem in say CC or SRG theories?
Appendix: Mathematical details
The original RBM had binary visible and hidden nodes. They were showned to be universal approximators of discrete distributions. It was also shown that adding hidden units yields strictly improved modelling power. The common choice of binary values are 0 and 1. However, in some physics applications, -1 and 1 might be a more natural choice. We will here use 0 and 1.
Here we look at some of the relevant equations for a binary-binary RBM.
$$
\begin{align}
E_{BB}(\boldsymbol{x}, \mathbf{h}) = - \sum_i^M x_i a_i- \sum_j^N b_j h_j - \sum_{i,j}^{M,N} x_i w_{ij} h_j.
\tag{17}
\end{align}
$$
$$
\begin{align}
p_{BB}(\boldsymbol{x}, \boldsymbol{h}) =& \frac{1}{Z_{BB}} e^{\sum_i^M a_i x_i + \sum_j^N b_j h_j + \sum_{ij}^{M,N} x_i w_{ij} h_j}
\tag{18}\\
=& \frac{1}{Z_{BB}} e^{\boldsymbol{x}^T \boldsymbol{a} + \boldsymbol{b}^T \boldsymbol{h} + \boldsymbol{x}^T \boldsymbol{W} \boldsymbol{h}}
\tag{19}
\end{align}
$$
with the partition function
$$
\begin{align}
Z_{BB} = \sum_{\boldsymbol{x}, \boldsymbol{h}} e^{\boldsymbol{x}^T \boldsymbol{a} + \boldsymbol{b}^T \boldsymbol{h} + \boldsymbol{x}^T \boldsymbol{W} \boldsymbol{h}} .
\tag{20}
\end{align}
$$
Marginal Probability Density Functions
In order to find the probability of any configuration of the visible units we derive the marginal probability density function.
$$
\begin{align}
p_{BB} (\boldsymbol{x}) =& \sum_{\boldsymbol{h}} p_{BB} (\boldsymbol{x}, \boldsymbol{h})
\tag{21}\\
=& \frac{1}{Z_{BB}} \sum_{\boldsymbol{h}} e^{\boldsymbol{x}^T \boldsymbol{a} + \boldsymbol{b}^T \boldsymbol{h} + \boldsymbol{x}^T \boldsymbol{W} \boldsymbol{h}} \nonumber \\
=& \frac{1}{Z_{BB}} e^{\boldsymbol{x}^T \boldsymbol{a}} \sum_{\boldsymbol{h}} e^{\sum_j^N (b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j})h_j} \nonumber \\
=& \frac{1}{Z_{BB}} e^{\boldsymbol{x}^T \boldsymbol{a}} \sum_{\boldsymbol{h}} \prod_j^N e^{ (b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j})h_j} \nonumber \\
=& \frac{1}{Z_{BB}} e^{\boldsymbol{x}^T \boldsymbol{a}} \bigg ( \sum_{h_1} e^{(b_1 + \boldsymbol{x}^T \boldsymbol{w}_{\ast 1})h_1}
\times \sum_{h_2} e^{(b_2 + \boldsymbol{x}^T \boldsymbol{w}_{\ast 2})h_2} \times \nonumber \\
& ... \times \sum_{h_2} e^{(b_N + \boldsymbol{x}^T \boldsymbol{w}_{\ast N})h_N} \bigg ) \nonumber \\
=& \frac{1}{Z_{BB}} e^{\boldsymbol{x}^T \boldsymbol{a}} \prod_j^N \sum_{h_j} e^{(b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j}) h_j} \nonumber \\
=& \frac{1}{Z_{BB}} e^{\boldsymbol{x}^T \boldsymbol{a}} \prod_j^N (1 + e^{b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j}}) .
\tag{22}
\end{align}
$$
A similar derivation yields the marginal probability of the hidden units
$$
\begin{align}
p_{BB} (\boldsymbol{h}) = \frac{1}{Z_{BB}} e^{\boldsymbol{b}^T \boldsymbol{h}} \prod_i^M (1 + e^{a_i + \boldsymbol{w}_{i\ast}^T \boldsymbol{h}}) .
\tag{23}
\end{align}
$$
Conditional Probability Density Functions
We derive the probability of the hidden units given the visible units using Bayes' rule
$$
\begin{align}
p_{BB} (\boldsymbol{h}|\boldsymbol{x}) =& \frac{p_{BB} (\boldsymbol{x}, \boldsymbol{h})}{p_{BB} (\boldsymbol{x})} \nonumber \\
=& \frac{ \frac{1}{Z_{BB}} e^{\boldsymbol{x}^T \boldsymbol{a} + \boldsymbol{b}^T \boldsymbol{h} + \boldsymbol{x}^T \boldsymbol{W} \boldsymbol{h}} }
{\frac{1}{Z_{BB}} e^{\boldsymbol{x}^T \boldsymbol{a}} \prod_j^N (1 + e^{b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j}})} \nonumber \\
=& \frac{ e^{\boldsymbol{x}^T \boldsymbol{a}} e^{ \sum_j^N (b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j} ) h_j} }
{ e^{\boldsymbol{x}^T \boldsymbol{a}} \prod_j^N (1 + e^{b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j}})} \nonumber \\
=& \prod_j^N \frac{ e^{(b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j} ) h_j} }
{1 + e^{b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j}}} \nonumber \\
=& \prod_j^N p_{BB} (h_j| \boldsymbol{x}) .
\tag{24}
\end{align}
$$
From this we find the probability of a hidden unit being "on" or "off":
$$
\begin{align}
p_{BB} (h_j=1 | \boldsymbol{x}) =& \frac{ e^{(b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j} ) h_j} }
{1 + e^{b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j}}}
\tag{25}\\
=& \frac{ e^{(b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j} )} }
{1 + e^{b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j}}}
\tag{26}\\
=& \frac{ 1 }{1 + e^{-(b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j})} } ,
\tag{27}
\end{align}
$$
and
$$
\begin{align}
p_{BB} (h_j=0 | \boldsymbol{x}) =\frac{ 1 }{1 + e^{b_j + \boldsymbol{x}^T \boldsymbol{w}_{\ast j}} } .
\tag{28}
\end{align}
$$
Similarly we have that the conditional probability of the visible units given the hidden ones are
$$
\begin{align}
p_{BB} (\boldsymbol{x}|\boldsymbol{h}) =& \prod_i^M \frac{ e^{ (a_i + \boldsymbol{w}_{i\ast}^T \boldsymbol{h}) x_i} }{ 1 + e^{a_i + \boldsymbol{w}_{i\ast}^T \boldsymbol{h}} }
\tag{29}\\
&= \prod_i^M p_{BB} (x_i | \boldsymbol{h}) .
\tag{30}
\end{align}
$$
$$
\begin{align}
p_{BB} (x_i=1 | \boldsymbol{h}) =& \frac{1}{1 + e^{-(a_i + \boldsymbol{w}_{i\ast}^T \boldsymbol{h} )}}
\tag{31}\\
p_{BB} (x_i=0 | \boldsymbol{h}) =& \frac{1}{1 + e^{a_i + \boldsymbol{w}_{i\ast}^T \boldsymbol{h} }} .
\tag{32}
\end{align}
$$